
Computer vision has long been dominated by convolutional neural networks, but the landscape is changing fast. Vision Transformers are redefining how machines understand images by applying transformer architectures directly to visual data. Instead of relying on local convolutional filters, ViTs learn global relationships across an entire image, leading to stronger generalization and scalability. This shift is driven by real-world needs such as large-scale image understanding, multimodal AI, and foundation models that work across domains. With Python libraries like PyTorch and Hugging Face making ViTs accessible, adoption has accelerated across research and industry. In this blog, we explore how Vision Transformers work, why they outperform traditional CNNs in many scenarios, and how developers can build and train ViT models in Python for modern, production-ready computer vision systems.
Deep Dive into the Topic
Vision Transformers apply the same core idea that transformed natural language processing to images. Instead of words, an image is split into fixed size patches. Each patch is flattened and projected into an embedding space, similar to token embeddings in language models. These embeddings are then processed by transformer encoder layers using self-attention.
The key innovation lies in global attention. CNNs focus on local neighborhoods and gradually build global context. Vision Transformers capture long-range dependencies from the very first layer. This makes them especially powerful for complex scenes where relationships between distant objects matter.
A typical ViT architecture includes a patch embedding layer, positional embeddings, multiple transformer encoder blocks, and a classification or detection head. Self attention allows the model to dynamically focus on the most relevant image regions.
Press enter or click to view image in full size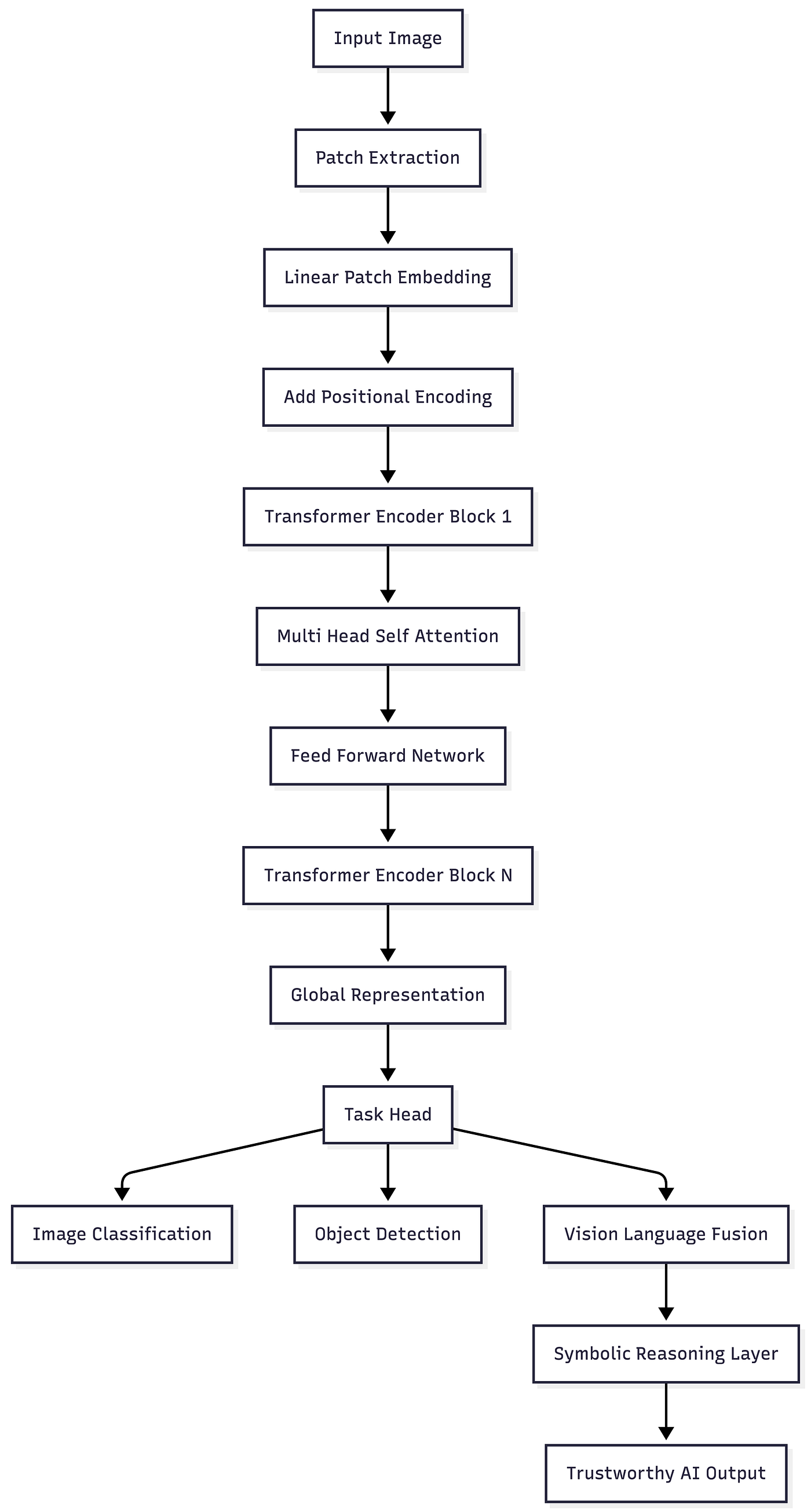
In production systems, Vision Transformers often sit inside hybrid AI systems. Neural perception is combined with symbolic reasoning, knowledge graphs, or rule engines to improve explainability and hallucination prevention. LangChain can orchestrate vision language pipelines, DeepProbLog can apply probabilistic logic on top of predictions, and PySyft can help enforce privacy when training ViTs on sensitive datasets. This combination pushes ViTs beyond raw accuracy toward trustworthy AI.
Code Sample
Step 1: Install dependencies
Step 2: Load dataset and model
Step 3: Training loop
Step 4: Visualize training loss
Pros of Vision Transformers
Global context understanding
- Self-attention enables holistic image reasoning.
Strong scalability
- Performance improves significantly with more data and compute.
Unified architecture
- The same transformer backbone works across vision and multimodal tasks.
Better generalization
- ViTs often transfer better across datasets than CNNs.
Thriving ecosystem
- Strong community support and pretrained models accelerate adoption.
Industries Using Vision Transformers
Healthcare uses Vision Transformers for medical image analysis, pathology slide classification, and radiology workflows.
Finance applies ViTs to document processing, identity verification, and fraud-related image analysis.
Retail benefits from ViT-powered visual search, product tagging, and automated catalog enrichment.
Automotive companies use ViTs for scene understanding, traffic sign recognition, and sensor fusion.
Legal organizations apply ViTs to document scanning, evidence classification, and visual data analysis.
How Nivalabs AI can assist in this
- Nivalabs AI designs end-to-end Vision Transformer solutions tailored to business objectives.
- Nivalabs AI brings deep expertise in Python-based ViT training and fine-tuning.
- Nivalabs AI integrates Vision Transformers with symbolic reasoning for trustworthy AI.
- Nivalabs AI focuses on hallucination prevention through validation and rule-based layers.
- Nivalabs AI builds hybrid AI systems combining vision, language, and knowledge graphs.
- Nivalabs AI ensures privacy and compliance using secure data handling practices.
- Nivalabs AI optimizes ViT models for performance and scalability.
- Nivalabs AI supports deployment across cloud and edge environments.
- Nivalabs AI provides explainability and monitoring for vision models in production.
- Nivalabs AI partners long-term to evolve computer vision platforms.
References
An Image is Worth 16x16 Words
Hugging Face Vision Transformers Documentation
PyTorch Vision Models
Conclusion
Vision Transformers represent a fundamental shift in computer vision, moving beyond the limitations of convolutional architectures. By modeling global relationships through self-attention, ViTs deliver stronger performance, flexibility, and scalability. This blog explored the inner workings of Vision Transformers, demonstrated a practical Python implementation, and highlighted real-world adoption across industries. As hybrid AI systems mature, combining Vision Transformers with symbolic reasoning and knowledge-driven validation will further strengthen trustworthy AI. For developers and decision makers, embracing Vision Transformers today is a strategic step toward building future-ready computer vision systems that scale with data, complexity, and ambition.


